Sometimes, TDD goes smoothly from story to story, or micro-story to micro-story. Other times, we aren’t clear how to proceed, and do a spike. But there’s a third approach I use occasionally, when I’m in a new area and want to get going quickly: Trailblaze and Pave.
Trailblaze and Pave
You know the design direction you want to take, or at least start with.
But that requires setting up more mechanism than you want to establish its essence.
So…
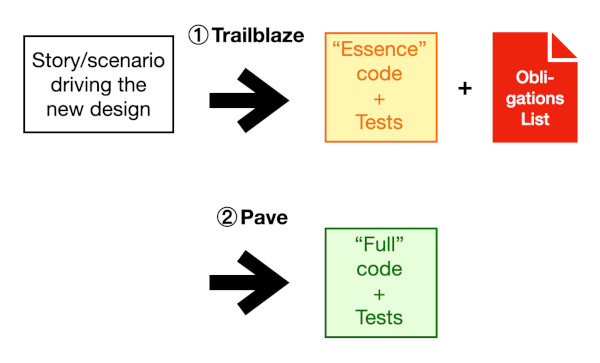
Choose a story or scenario that shows the benefit of the chosen design approach.
Trailblaze: TDD as quickly as you can to get the shape right for the design at the heart of your solution (“the main focus”). Take whatever shortcuts you want, provided you know how to address them properly later. These shortcuts form obligations – and you must keep a list of them. Go just far enough on your main focus to establish the critical things you want, not implement everything about it.
Then Pave: Come back to your obligations list, and address each one. I prefer to treat them as “extra” refactorings and code you need to write before the next story, rather than things to do as part of the next story or micro-story.
I try to do both the trailblazing and paving in a single session.
Example
Suppose I want to implement a new financial algorithm over a portfolio of assets. The algorithm operates on money, but I don’t have a value type for it yet. I only need “+” and “*” (money times constant) for now. I might define an asset class that only has enough information for my algorithm. For the portfolio, I might just use an array for now, even though it should be a wrapped type.
It looks like this:
| Actions | Obligations |
| * Define a Money class with “+” and “*” In Java – define a new class with only the needed methods In Swift – define Money as a type alias for Double | * Turn Money class into a value type – equality test – hashable? – proper handling of values (no “double” arithmetic) |
| * Define Asset class with two fields | * May need more info in Asset class |
| * Use an array for the portfolio | * Wrap a Portfolio class |
| * Get the financial algorithm working | * Edge cases for algorithm |
I introduce most classes I’ll need, but make them as minimal as possible. This lowers the amount of code that must be changed. Thus, my tests all use Money(100) rather than a direct literal 100, so backfilling a proper Money class won’t change those tests.
Trailblaze and Pave versus …
These approaches are comparable but different:
- Walking Skeleton: (See References.) A walking skeleton accomplishes something across multiple components, but at a whole-system scale. With a walking skeleton, you’re not trying to implement any real algorithm but rather get the structure right. With Trailblaze and Pave, you are trying to implement real behavior.
- Spike: A spike may cut through multiple layers of a new design, but it’s explicitly willing to take any shortcut that gets the learning more quickly. The spike is then thrown away. A spike need not use tests, good design, refactoring, etc., but those are an important part of Trailblaze and Pave.
- Spike and Stabilize: (See References.) This approach takes the shortcuts of a spike, but keeps the spike, and then backfills design and refactoring. It doesn’t bother with tests during the spike, or tracking the shortcuts taken. By contrast, Trailblaze and Pave is more for when you pretty much know where you’re going, and it takes time during trailblazing to create the “punch list” used by paving.
Roots
I haven’t seen this tactic described or mentioned before, but I’ve used it for a number of years.
One influence, for which I don’t have a reference, was a design bake-off at OOPSLA many years ago. The problem was some sort of bank account, where you needed to compute the balance. Ward Cunningham and Kent Beck made an initial version something like:
[1, 3, 5].reduce(+)(I’ve certainly messed up the syntax.) What I liked about this was that it cut through to the heart of the problem. This positions them to wrap the data and develop the full approach, rather than introducing objects first as I described above.
Another influence is from watching Kent Beck do TDD, writing a file card with test and other ideas as he went. (He demonstrates this in his book; see References.) In some ways, I’m formalizing that some list items are ideas, but others are obligations, and I’m emphasizing the situation of quickly building up new objects supporting a new design, rather than “the next feature”.
(Their influence was important, but is not an endorsement by them:)
Limits
I use the Trailblaze and Pave approach only occasionally – 5% of the time? Less? Certainly not more. More typically, I do “normal” TDD of the next feature, with spikes as needed.
Why? Trailblaze and Pave puts a tension on the system: you have to commit to both trailblazing and paving. If not, you have potential errors, and certainly a design you wouldn’t normally accept.
I transform that tension into physical tension in my body, and try to be aware of how much I’m stacking up, and how unstable it’s becoming. I have mental limits (lower every year, I suspect), so I don’t want to get outside the bounds of what I can catch up to.
A slower but safer way is to spike: spike the new approach, delete it as usual, then re-implement it from scratch with TDD.
Conclusion
Trailblaze and Pave is a way to more quickly introduce new objects and design elements, at the cost of taking more care while you do it. It’s an alternative to “Spike and Re-Implement” or “Spike and Stabilize”.
Choose a story or situation that gets at the heart of the reason you want a particular design, then…
Trailblaze: Quickly develop toward the key new design, but explicitly keep track of any shortcuts as a list of Obligations.
Pave: Go back and meet those obligations, so the new design appears to have been properly done by TDD – tested and refactored.
References
“Beyond Test Driven Development“, by Liz Keogh. Retrieved 2021-02-23. Describes “Spike and Stabilize” approach.
Test-Driven Development: By Example. Kent Beck.
“Walking Skeleton“, by Alistair Cockburn. Retrieved 2021-02-23.