Oracles are things that can tell us whether or not a result is correct.
For some tests, an oracle is as simple as comparing a couple strings or numbers. Other tests have many acceptable results and it’s harder to know what’s right. I refer to oracles that have to account for many possible results as combinatorial oracles.
Examples
Here are some examples where multiple results are acceptable:
- Generating Text: On Unix-based systems, the line separator is \n; on Windows, it’s \r\n.
- Generating HTML: There are plenty of opportunities:
- Case distinctions matter in some places but not others.
- Spaces matter in some places but not others.
- Quotation marks can be omitted in some cases.
- The order of attributes is not significant.
- Sorting: If only part of a record is used as a key, then two valid sorts may result in different orders.
- Randomness: When part of a computation is based on randomness, the exact output may not be known.
- Threading: Threading can result in computations having different (valid) results.
- Numerical Accuracy: With floating-point numbers, different approximations may be acceptable, and we may allow a range of answers. Some of this is from the inherent loss of accuracy ( (1.0/10.0)*10.0 != 10.0); some is from unexpected rules of arithmetic (sometimes
(a+b)+c != a+(b+c)). - Undefined Behaviors: In some languages or libraries, behavior is non-deterministic. For example, hash codes may vary from run to run; enumerators may promise to deliver items exactly once but not in any deterministic order.
- Combinatorial Results: The software may be computing a list of all variants, with no defined order. Or, you may want one of a number of possibilities, and not care which one.
To summarize, simple oracles suffice as long as you’re producing, a single, well-defined, deterministic result, via code that makes no use of floating point, hashing, undefined behavior, randomness, or enumerations.
Simple Oracles
Simple oracles compare against a single result.
Atomic Equality
 Atomic values such as boolean, integer, or character (in many languages) can be compared directly:
Atomic values such as boolean, integer, or character (in many languages) can be compared directly:
assertEquals(3, calculatedValue)
In many languages, strings are treated almost as simply:
assertEquals("expected string", actualString)
(In other languages, strings are tested with compound equality, up next.)
Compound Equality
 Some values aren’t atomic, but rather are structured out of other values. Three common examples are arrays, records, and objects.
Some values aren’t atomic, but rather are structured out of other values. Three common examples are arrays, records, and objects.
For arrays, we want to know that the arrays have the same length, and that the same values are at the same location.
Records (structs) may be considered equal if they have the same fields, and each corresponding field value is equal. (Some languages might require that they have the same type; others use “duck typing”.)
Objects are similar to records as far as their values, but their type may be involved when testing equality.
Equality can have special meaning with fields or objects, where only a subset of fields may be of interest. For example, a field might be used as a cache for other values, and we care that those other values are equal regardless of the state of the cache.
Furthermore, there are different types of equality. In structural equality, objects are equal if they have the same values inside. In referential equality, objects are considered equal only if they point to the same object.
With objects, it’s common to define an equality test on the object, so it can apply the proper rules.
Combinatorial Oracles
When multiple answers are acceptable, there is no single best way but rather a toolbox from which to draw.
Oracles that Ignore Problems
Ostrich
 The first strategy, if you want to call it that, is the easiest: don’t worry about it, and hope it doesn’t become an issue. (I call it an Ostrich strategy because of the myth that the ostrich hides its head in the sand.) Sometimes this approach is applied accidentally, sometimes it’s applied intentionally.
The first strategy, if you want to call it that, is the easiest: don’t worry about it, and hope it doesn’t become an issue. (I call it an Ostrich strategy because of the myth that the ostrich hides its head in the sand.) Sometimes this approach is applied accidentally, sometimes it’s applied intentionally.
This strategy can certainly cause pain. Have you ever heard (or said!), “Works on my box”?
But the ostrich approach can be a useful way to go from “works nowhere” to “works somewhere” even if it can’t quite reach “works everywhere.”
Oracles that Limit Solutions
One approach is to find ways to limit what is acceptable.
Constrain Solutions
 You may be able to impose additional restrictions on what solutions are acceptable.
You may be able to impose additional restrictions on what solutions are acceptable.
For example, a document format such as HTML allows mixed-case tag names. You could add a constraint to your solution, deciding that only lowercase tag names will be acceptable to you, and test accordingly.
This is not a perfect approach. Suppose you have a third-party HTML library that would otherwise meet your needs, but it doesn’t meet the lowercase constraint. You could use it anyway and transform its output (extra work), or build or find something else that meets the constraint (at extra development work or cost), or remove the constraint (causing extra work on the testing side).
Clamp
 Variation may be desirable in your solution overall, but you can clamp it down for testing purposes.
Variation may be desirable in your solution overall, but you can clamp it down for testing purposes.
A prime example of this is using a random number generator. Your app may normally use a system-generated seed (based on the clock or another random or pseudo-random source). However, you may be able to force your own seed instead for testing purposes, and get consistent results you can test with. (This approach is not very helpful for Test-Driven Development, but does allow testing afterwards.)
Alternatively, you could replace the random number with your own source of numbers, to force particular situations. (This is more useful for TDD.)
None of these are a full guarantee, as the random number generator might not be the only cause of combinatorial results.
Oracles that Account for Possibilities
One way to handle multiple solutions is to deal with them.
Enumerate Explicitly
 If the set of possibilities is small, you can structure your test to explicitly try the valid possibilities.
If the set of possibilities is small, you can structure your test to explicitly try the valid possibilities.
For example, instead of checking:
"a b".equals(result)
which presumes an order, you could test:
"a b".equals(result) || "b a".equals(result)
or, said another way:
result in ["a b", "b a"]
This becomes tedious for two or three possibilities, and unbearable for more.
Accept Ranges
 If a set of values in a range are all acceptable, we can explicitly test the range.
If a set of values in a range are all acceptable, we can explicitly test the range.
While ranges are occasionally useful for things like integers or characters, they are most common for floating-point numbers:
FUZZ = 0.00005 ... assertEquals(0.10, 1.0/10.0, FUZZ)
Exact equality of floating-point numbers is possible, but is too much of a constraint for most applications. The range test is instead:
abs(actual - expected) <= fuzz
Canonical Form (Normalized)
 When there are many possible outputs, one approach is to put objects in canonical form: a unique representation for each equivalent object. (This process is sometimes called normalizing although some people give those words different meaning.)
When there are many possible outputs, one approach is to put objects in canonical form: a unique representation for each equivalent object. (This process is sometimes called normalizing although some people give those words different meaning.)
We can compare the canonical form of two things to more easily decide if they’re equivalent.
For example: For HTML, remove extraneous spaces, use newlines only after each closing tag, use lowercase tag and attribute names, and put attributes in alphabetical order. At that point, you may be able to just compare strings.
Remember that the expected value must either be written in canonical form, or converted to canonical form before comparing.
Robust Membership Test
 We may not want or be able to enumerate all valid results, but we may be able to test values to see if they’re valid.
We may not want or be able to enumerate all valid results, but we may be able to test values to see if they’re valid.
Example: Puzzle Builder. Suppose we are given a set of words with the goal of producing a grid of letters that can yield those words, played by Boggle™ rules: move letter by letter to adjacent letters in order to build up a word.
Given the words CAT, PIN, TAP, POD, this would be a valid answer:
C A T D P N O I E
So would this:
C A D T P O X I N
If there is any solution, there are many solutions, since mirroring and rotation can easily produce 20 variants of almost any solution. (Thanks Abstract Algebra class! I knew you’d be handy some day.)
It may not be practical to manually enumerate all possible solutions.
But we can devise a robust membership test: Build a solver that takes a puzzle and a dictionary of words, and tells which of those words appear in the puzzle. The solver can recognize any valid solutions even though it’s not capable of generating them.
Oracles that Subset Possibilities
Subsetting has us only look at the critical parts of results.
Filter
 A result may mix information we don’t care about with information we do. We can filter: throw away the parts we don’t care about and compare what is left.
A result may mix information we don’t care about with information we do. We can filter: throw away the parts we don’t care about and compare what is left.
For example, we might decide that <!--comments--> should be ignored in an HTML document. We could filter out comments before comparing HTML documents (perhaps using the canonical form approach).
Perhaps the most common example: filter out \r so that only \n separators need to be compared:
result.replace("\r\n", "\n")
This can hide problems; if our Unix code were wrongly generating \r\n, we wouldn’t be able to tell.
Probe
 The data you’re most worried about may be only a portion of a larger structure. It may be more important to know that the right things are present, and less important to worry about extra things you don’t care about.
The data you’re most worried about may be only a portion of a larger structure. It may be more important to know that the right things are present, and less important to worry about extra things you don’t care about.
For example, you have an HTML tag where you expect to see an id attribute with bar, a selected attribute with true, and a display attribute with fill.
Rather than enumerate the permutations reflecting all possible orderings (which still may not be enough if other attributes are involved too), you can probe:
result.contains(" id=\"bar\"")
result.contains(" selected=\"true\"")
result.contains(" display=\"full\"")
Notice that there’s a space before each attribute name, so we’re not fooled if there is an attribute such as fluid="bar".
Statistical Analysis
 Especially if randomness is involved, you may be able to devise statistical tests that give you feedback about your results.
Especially if randomness is involved, you may be able to devise statistical tests that give you feedback about your results.
For example, you’re flipping a coin to result in a sequence of random 0s and 1s. You would not expect to know the exact sequence, but you would expect to have about half of each in 50 flips. (The exact meaning of “about” is left as an exercise to your local statistician.) This test isn’t perfect – any pattern could happen if run often enough – but it would be enough to flag anomalies.
Statistics can be defeated by an evil opponent. Suppose someone intentionally returns 25 0s followed by 25 1s, knowing our test would pass but our numbers weren’t random.
We have to draw a line and decide when the statistics are good enough, and what we’ll do about the occasional false failure.
Abstract Property
 We may not be easily able to compare equality, but sometimes it’s possible to define some abstract property of our objects and compare those.
We may not be easily able to compare equality, but sometimes it’s possible to define some abstract property of our objects and compare those.
For example, XOR (^) lets us combine two values and produce a scrambled value that doesn’t depend on the order of the combined values: -3024 ^ 1177 == 1177 ^ -3024
Going back to our example of HTML tags with attributes, we could XOR the characters in the tag and attributes, and compare that, rather than comparing strings or enumerating variations. The XOR’d value is a sort of signature for that tag.
Axiomatic Property
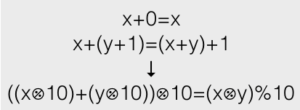 In some cases, the object you’re testing conforms to an explicit set of axioms.
In some cases, the object you’re testing conforms to an explicit set of axioms.
You can define a property, and then specify how that property changes in relation to each axiom.
This isn’t a common tool; I’ve only used it for collection-like objects, and even then only rarely.
Example: Let’s look at a stack:
top(empty) = error top(push(e, s)) = e pop(empty) = error pop(push(e, s)) = e isempty(empty) = true isempty(push(e, s)) = false
Consider two abstract properties: size and signature.
size(empty) = 0 size(push(e, s)) = 1 + size(s) size(pop(push(e, s))) = size(push(e, s)) - 1 signature(empty) = 0 signature(push(e, s)) = signature(e) ^ signature(s) signature(pop(push(e, s))) = signature(e) ^ signature(push(e, s))
We could compare two collections by looking at their sizes only. This is abstract, but vulnerable to failure if the wrong elements are in the collection.
Alternatively, we could use the signature, which XORs together the hash codes of the elements. This is harder but not impossible to fool.
The axiomatic property approach requires that we know what operations will be applied, in order to compute the expected signature.
Conclusion
We’ve looked at several approaches to creating oracles. The next time you’re building an oracle, consider these techniques (alone or in combination):
| Ideas for Oracles |
|---|
Simple Oracles
|
Ignoring Problems
|
Limiting Solutions
|
Accounting for Possibilities
|
Subsetting Possibilities
|