Software is hard to create. (This isn’t news.)
All we want is two things: everything we have, and more. Is that too much to ask?
Stability and progress conflict: changes we make for progress threaten stability.
Test-driven development is a response to this: TDD is an evolutionary strategy to resolve the tension between progress and stability.
TDD works by starting with a stable base, and making moves that maintain stability in the face of change.
TDD is an evolutionary strategy to resolve the tension between progress and stability.
Evolving Needs
How can we cope with the need to evolve code?
One way is to try to anticipate all, or the most likely, or the most important set of future needs, and design a solution that can accommodate them. Then, in the future, when a need manifests, we expect implementation to be quicker than it otherwise would.
TDD regards that approach as risky:
- It’s hard to anticipate future needs accurately.
- If the new design is wrong, we have to pay both to rip out the wrong solution as well as create the right one.
- Even if we guess right, we’ve slowed down development and maintenance of current needs in favor of fuzzy future needs.
Instead, TDD uses an evolutionary approach: Build the system with a design that works for today’s needs, and evolve it to cover new needs as they emerge.
The Deep Rhythm of TDD
Red-Green-Refactor describes the rhythm of TDD. However, it tells “what” is happening, and not “why”.
TDD has a deeper rhythm, the “why” for the moves we make: expand-consolidate. Progress and stability. Tension and release. Breathe in, breathe out.
TDD is incremental and evolutionary — each expansion is a small step outside the current capabilities: one new test.
TDD Moves
Red+Green and Refactor are two moves we make, perhaps the most common, but there are others as well. I’ll classify the TDD moves as stabilizing, progress-oriented, neutral, or destabilizing.
Stabilizing: Refactoring to Improve Design, Confirmatory Test
Progress-Oriented: Preparatory Refactoring, Red+Green, Generalization, Upgrade Dependency
Neutral: Push/Pop Test Context, Explore/Study, Spike
Destabilizing (not TDD): Untested Code, Checked-in Spike, Test-After Code, Large Checkin
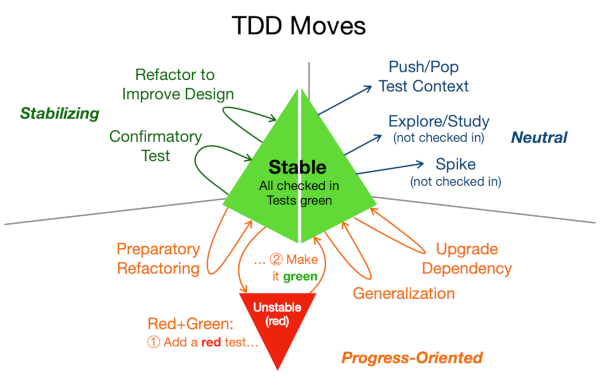
After each move, you check in the code with the intent of creating a new stable baseline.
Each move is a brief foray into an instability (even refactoring has risks!), with a return to stability.
The Context
TDD takes place in a context.
For Agile teams, there’s a culture of collaboration, including people looking at code together: pairing, ensemble (mob) programming, perhaps code reviews.
Many Agile teams use Continuous Integration, often in a trunk-based way. CI tools usually reject any builds that don’t pass the tests. This contributes to stability.
Some teams have a Continuous Deployment or Delivery capability: checkins that pass tests go on to be deployed to some or all users. Testing and partial rollouts help with stability too. Even real use helps: users will definitely let you know if there are stability problems.
There are more processes supporting stability: automated monitoring, testing in production, “dark launch” capabilities that simulate loads before features are visible, and so on.
Do what you can to create a supportive context for TDD. All of the ideas are compatible with TDD, but they’re outside the bounds of how we look at TDD below.
Source Control
It’s been years since I had to ask a team, “Have you ever considered source control?” Many descriptions of TDD don’t mention it. Teams using TDD know that if you keep the build “green”, never checking in failing tests, you get a ratchet effect on your code – stability.
With a little care, you can create code that is not just green, but safe to deploy as well. (In some cases, this is done by not making it accessible to real users just yet.)
In TDD, you can check in after each safe move (though not in the middle of a Red+Green move). While some people wait for a few cycles or until the end of a session, the best programmers I know tend to check in much more frequently.
There are several relevant articles in the references: Tim Ottinger’s article on micro-commits; Kent Beck’s article on TCR (a relative of TDD where you check in or revert after each move); my article comparing TDD with TCR, and another article of mine on ratchets.
Stabilizing Moves
Stabilizing moves make the existing system better and safer at doing what it already does.
Refactoring to Improve Design
This is the classic refactoring (part of red-green-refactor but also useful outside of it). In this case, the system works, but its code may still be too complex, contain duplication, or hard to understand.
So, refactor to “improve the design of existing code without changing its behavior”.
This results in a system that is easier to understand and maintain.
Confirmatory Test
Confirmatory tests are those that we expect to run green the first time they’re run.
Are they redundant? Perhaps. (Perhaps not, if you’ve been generalizing.) We create confirmatory tests because they boost our confidence.
For example, suppose we have created a series of tests that convince us the parts are working. We can also create a confirmatory test that tries a number of parts together (a small-scale integration test). This test can guard against future changes that break existing work.
Progress-Oriented Moves
Progress-oriented moves are designed to increase the capabilities of the system.
Preparatory Refactoring
Preparatory refactoring is for when we’d like to extend behavior, but the existing design makes the new behavior a stretch too far. So, we anticipate a design, “If the system were designed like this, the new behavior would be easy to add.” Then we apply refactoring transformations in reverse of their usual direction. (For example, add an unused parameter instead of removing it.)
I have an example of this in the elm interpreter I’m working on. The next feature is to support definitions, so somebody can write “x = 3” or “square n = n ^ 2”. There’s a well-known way to handle this in interpreters: pass a symbol table (“context”) into the expression nodes. Then an expression can look up “x”, and see that we can substitute “3”.
My nodes don’t take parameters. But I did a preparatory refactoring to add a SymbolTable as a parameter to the nodes, even though no nodes require it yet. (I later test-drove some primitive SymbolTable behavior.)
If I had instead started with the evaluation of “x = 3; x” at the node level, I’d immediately “discover” that I need some sort of symbol table with a value for “x”. The change for that is big enough for its own development episode, so I’d have to defer the first test and start new ones.
With preparatory refactoring, the “right” design will already be in place, making for an easier implementation of the new behavior.
Preparatory refactoring has a couple risks. One is that the design is not a good fit, and has to be re-done. The other is that there’s some delay and we leave over-complicated code in the system. (This is the speculative generality smell.)
See Martin Fowler’s articles on preparatory refactoring and refactoring workflows in the references.
Red + Green
To modify the system to support new behavior, use TDD’s three-step red+green process:
- Write a test that’s expected to fail.
- Run the test to see it fail (“Red”).
- Write or change code so that the test passes (“Green”).
The test is intended to just slightly expand the system’s behavior, and the new code is intended to be “just enough” to pass.
Side note: TCR takes a slightly different approach here:
- Write a test that would fail now but we expect to pass with the intended new behavior.
- Write code that provides the new behavior.
- Run the test: if it passes, check in both test and code; if it fails, revert both.
Whether TDD or TCR, we get a new behavior along with its test.
Such tests help us in a few ways:
- It’s a small step, done from a concrete case. A small step is easier to get right.
- The test drives out decisions: What’s the right interface? What’s important? What does it do?
- The test serves as a regression test, supporting refactoring and future changes.
Kent Beck’s TDD book (in the references) describes many useful patterns for Red+Green (plus many others!).
Generalization
When the system works for certain inputs but we’d like it to work for more inputs, we may generalize existing code.
A generalization is a transformation that changes the way the system responds to some inputs, without changing its behavior with regard to existing tests. The existing tests provide a guard rail against (some) breaking changes.
See the contrast with refactoring? Refactoring preserves behavior for all potential inputs; generalization preserves behavior only for currently tested inputs.
This move corresponds to Kent Beck’s “Fake It ’Til You Make It”, which generalizes from one example. (His “Triangulation” generalizes from two or more examples.) See his TDD book in the references.
Refactoring preserves behavior for all potential inputs; generalization preserves behavior only for currently tested inputs.
Upgrade Dependency
Software typically depends on many other layers of software, and rarely does a team “own” all of them.
When a depended-on component gets upgraded, you may want or need to modify your system to include a more recent version.
I’ve listed this as progress-oriented, but it can have a negative effect on your stability. (That depends on both the component and your software.)
Neutral Moves
Neutral moves neither grow the software’s capabilities, nor improve the design.
Push/Pop Test Context
Sometimes you go to work on a test, and you realize you’ve got to do another test. Maybe in doing that, you find still another thing. You can treat these like a stack, deferring them by commenting out the test, possibly reverting some code, while you go off to solve the “inner” problem.
I had an example this morning: a method was creating a new object, but the new object needed its own equals method before it could be used in my test. So I temporarily marked the first test to be ignored while I worked on the other. I also discovered it would be nice to have a debug string, so I took care of that too before returning to the original test.
(I’m calling this neutral, because switching what you work on is neutral, but the work itself is stabilizing or progress-oriented.)
Explore/Study
There are times you need to understand how things work, or where new things might fit in. Reading code is a fine activity for a programmer! We often need to explore and study. The result is learning, not checked-in code. See the video by Mike Hill in the references.
Spike
A spike is an exploratory programming session. You write code, intended to quickly prove out an approach, but ultimately throw it away. The benefit is the learning you do, not the code you created.
Tests are not required; “proper” design is not expected. Rather, you’re trying to learn quickly, so you’ll only worry about tests or design if they help you go faster.
Destabilizing Moves (not TDD)
Some moves aren’t part of TDD, though they may happen anyway. They aren’t guaranteed to destabilize the system, but they definitely risk doing so.
Untested Code
“It’s easy / trivial / straight-forward, and doesn’t need a test.” While just adding code may add capabilities, it increases the risk of error. Without tests, you don’t get the benefit of the incremental design that TDD typically creates, and you can’t detect if the new code starts failing.
If you’re only using TDD for say the business logic of a system, you may find yourself adding untested code for say the user interface. You’ll need to take other steps to ensure the stability of the system.
Checked-In Spike
If you set out to do a spike, but then check it in, you’re basically in the same position as someone who checks in any other code without tests. Maybe worse, because a spike often intentionally shortcuts design.
Test-After Code
I can’t say it’s always destabilizing, but code with tests designed afterwards is often over-engineered, tends not to have as testable an interface as TDD-written code, and often has over-complicated and slow tests.
But, I have to admit that many projects have used this style, and you do still get a suite of unit tests for regression testing that supports refactoring.
Large Checkins
We discussed checking in on every green, or even just once per session, but some people check in days’ or even weeks’ worth of code all at once. Even if the code is developed TDD style (which it often isn’t), you’re losing the benefits of ongoing feedback, and a large move risks destabilizing the system.
Conclusion
The deep rhythm of TDD is expand – consolidate. By taking small steps when expanding, you get constant feedback. By consolidating the expansion, you facilitate stability.
You can think of TDD moves as progress-oriented, stabilizing, or neutral.
Progress-oriented moves: Preparatory Refactoring, Red+Green, Generalization, Upgrade Dependency.
Stabilizing moves: Refactoring to Improve design, Confirmatory Test.
Neutral moves: Push/Pop Test Context, Explore/Study, Spike.
A stable base is critical to TDD. Create a context that supports it: collaboration, source control, continuous integration, continuous deployment, etc.
With TDD done well, you have an evolutionary approach that’s never more than half a move away from a working system.
References
Beck, Kent. “test && commit || revert”. Retrieved 2021-02-15.
Beck, Kent. Test-Driven Development: By Example.
Fowler, Martin. “An example of preparatory refactoring”. Retrieved 2021-02-15.
Fowler, Martin. “Workflows of Refactoring”. Retrieved 2021-02-15.
Hill, Mike. “Optimizing a Program (and Programming” . Retrieved 2021-02-16.
Marick, Brian. “XP’s Tuning Mechanism: Operational Stability + Triggered Disruption“. Retrieved 2021-03-11. [From followup discussion on Twitter.]
Marick, Brian. “Cheating Decline: Acting Now to Let You Program Well for a Really Long Time“. Retrieved 2021-03-11. [From followup discussion on Twitter.] TDD discussion starting at 36:30.
Ottinger, Tim. “What’s this about Micro-commits?”. Retrieved 2021-02-15.
Wake, Bill. “Ratchets Capture Progress: Steps to Continuous Integration”. Retrieved 2021-02-15.
Wake, Bill. “TDD, TCR, and Frequent Commits”. Retrieved 2021-02-15.