Today we’ll look at how to implement state machines as direct code. In part 1, we looked at what state machines are. In part 2, we looked at how you might implement them with an interpreter that process a data structure representing a graph. We also looked at what happens if a state machine is implicit: it may behave properly but be hard to understand.
The “State Machines” Series
Oh No – Go To!
The most direct way to code a state machine works for languages with goto statements: Assembler, BASIC, FORTRAN, …
Setup:
- Number the events 1..k
- Use EVENT_DONE (0) to represent “no more events”
- Number the states 1..s
- Use STATE_ERROR (0) to represent the error state
We’ll return the state number (or 0) when something is recognized.
Notice how straightforward this translation is; you can do it manually, or even have a state machine compiler that did it.
Prelude Code:
goto <initial state #>
For each state S:
<N>:
event = nextEvent()
For each edge “event e leads to state x” add:
if event == e goto <state-number-x>
If this is a final state:
if event == 0 return <N>
Finally:
return STATE_ERROR
If you have an action you want done on state entry, put it between the label and the assignment to event.
If you have code for the transitions, put it between the if and goto:
if event == e {
// action code
goto <state-number-x>
}
Example
Here’s the state machine for numbers again (that we used in part 2):
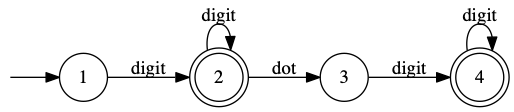
And here’s our goto-oriented code:
goto 1 1: event = nextEvent() if event == digit goto 2 return STATE_ERROR 2: event = nextEvent() if event == digit goto 2 if event == dot goto 3 if event = 0 return 2 return STATE_ERROR 3: event = nextEvent() if event == digit goto 4 return STATE_ERROR 4: event = nextEvent() if event == digit goto 4 if event == 0 return 4 return STATE_ERROR
Critique: Is this a good way to do state machines? Perhaps, if you’re generating this as assembly code. It cuts out some overhead compared to other approaches, so it may run more efficiently. (We can’t easily predict performance when systems use caches, branch prediction, and other low-level tricks .)
You may be able to optimize this approach further. If you know which events are most frequent, you can put them first. If the event list is dense (almost every event is used from the state), an indexed goto may be faster than a series of “if” tests. (An indexed goto is one way to implement a switch statement: it has a table indexed by events, where each slot is a goto target.) See “Very Fast LR Parsing” [abstract] for an application of this to parsers.
The Ole Switch-aroo
You may have never seen a real goto before; you may have never even programmed in a language that has one! Most languages have an alternative: a loop and a switch statement.
We’ll keep the state numbers as before, but you could use enums etc.
Prelude:
int state = <initial-state>
while true {
switch state {
For each state <N>:
case <N>:
event = nextEvent()
For each edge “event e leads to state x”:
if event == e { state = <x> } else
If the state is final:
if event == EVENT_DONE { return <N> } else
Then:
return 0;
break; // if needed
Postlude after all states:
} // switch
} // while
Example
Same state machine:
While+switch code:
int state = 1
while true {
switch state {
case 1:
event = nextEvent()
if event == digit { state = 2 } else
return 0;
break;
case 2:
event = nextEvent()
if event == digit { state = 2 } else
if event == dot { state = 3 } else
if event == EVENT_DONE { return 2 } else
return 0;
break;
case 3:
event = nextEvent()
if event == digit { state = 4 } else
return 0;
break;
case 4:
event = nextEvent()
if event == digit { state = 4 } else
if event == EVENT_DONE { return 4 } else
return 0;
break;
} // switch
} // while
Critique: While this is structured in the structured-programming sense, it’s not structured in the sense of having a structure that tells you the story of what’s going on. I’ve used this approach to transliterate unstructured code into a modern language, then refactored toward understandable code. (For example, “Refactoring Challenge – The Amazing Maze“.)
Structured State Machines
Some (but not all) state machines have the shape of a structured program: they can be represented with if, while, and sequence. State machines that don’t have this form can still be handled, using duplication and/or extra variables, but I’m not going to explore that.
I’ve seen this program structure used a lot with compilers. If you’re not using a tool (typically lex or one of its descendants), this is probably your approach. By luck or by planning, the tokens in most programming languages seem amenable to this.
Example: Numbers
Here’s the number state machine one more time:
Code, assuming characters are the events:
ch = nextch()
:
if isDigit(ch) {
while isDigit(ch) {
ch = nextch()
}
if digit != '.' return 2;
ch = nextch()
if !isDigit(ch) return 0;
while (isDigit(ch)) {
ch = nextch()
}
return 4;
} else ...
In this case, we only return an error if we find an error in the middle of a token. Otherwise, we’re done, and leave the next character ready for the next token matching to find it.
Example: Comments
Numbers and comments are often the trickiest elements in a language syntax, so let’s tackle a comment.
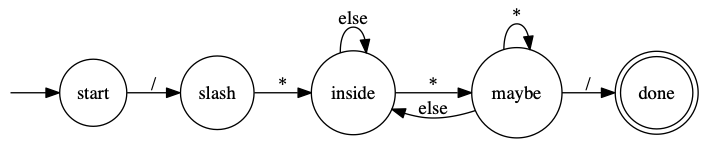
(In the code below, I’ll assume a “/” by itself is a token too i.e., pretend that “slash” is a final state too.)
ch = nextch() // prime the pump
:
if ch == '/' {
ch = nextch()
if ch != '*' { return TOKEN_SLASH }
ch = nextch()
repeat {
while ch != '*' {
ch = nextch()
}
while ch == '*' {
ch = nextch()
}
} until ch == '/'
ch = nextch()
} else if ch == ... // on to the rest
As you can see, even though the state machine looks a little complex, the code isn’t that hard to write.
This approach is related to recursive descent for parsers, but without the recursion. A state machine corresponds to a regular expression, and a regular expression can be regarded as a restricted grammar lacking recursion.
Critique: In the domain of tokenizers (aka lexers) for programming languages, this is a tedious but often acceptable approach. (The most popular alternative is to use a lexical analyzer generator.) You can split it into separate methods to make it easier to understand. This is an improvement over gotos or switch statements that bounce around willy-nilly. But you can also see why people might prefer a tool.
In real use, you have to handle unexpected end-of-file and other errors, and you often have other bookkeeping too. This turns something straightforward but tedious into something less straightforward and even more tedious.
State Design Pattern
The State pattern lets an object change its behavior, as if it were an instance of a different class, by delegating to objects that represent states. (If you’re familiar with the Strategy pattern, this is an instance of that, where the states are strategies.)
You implement this in two parts:
First, have a “context” class that is the main interface. (Other classes know it, but they won’t know the state classes directly.) The context knows the current state, and has a method changeState() that tells it to change state. It has a method for each event type, and each method someEvent() is implemented by delegating to state.someEvent(this).
The second part is the states. Have a parent class (or interface/protocol) that has an abstract method for each event. Have one child class per state, implementing behavior associated with each event. If there is a state change, it tells the context object which state to switch to.
Example
We’ll sketch out this approach for the Yacht example. Notice there are three events: roll, toggle, and choose.
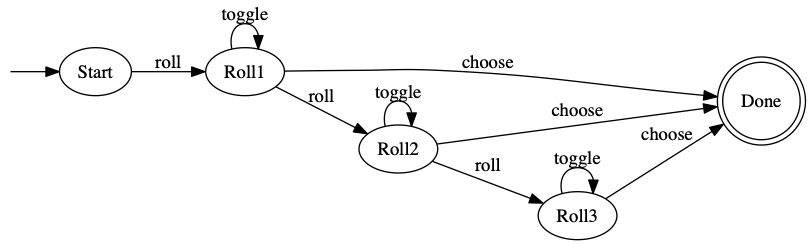
class Turn {
private TurnState state
void switchState(TurnState newState) { state = newState }
public void roll() { state.roll(this) }
public void toggle() { state.toggle(this) }
public void choose() { state.choose(this) }
}
class TurnState { // Parent of states; ignores events by default
public void roll(Turn t) { }
public void toggle(Turn t) { }
public void choose(Turn t) { }
protected void switchState(Turn t, State s) { t.switchState(s) }
}
class Start : TurnState {
public void roll(Turn t) { switchState(t, new Roll1()) }
}
class Roll1 : TurnState {
public void roll(Turn t) { switchState(t, new Roll2()) }
public void toggle(Turn t) { /* semantic action here */ }
public void choose(Turn t) { switchState(t, new Done()) }
}
class Roll2 : TurnState {
public void roll(Turn t) { switchState(t, new Roll3()) }
public void toggle(Turn t) { /* action here */ }
public void choose(Turn t) { switchState(t, new Done()) }
}
class Roll3 : TurnState {
public void toggle(Turn t) { /* action here */ }
public void choose(Turn t) { switchState(t, new Done()) }
}
class Done : TurnState {
}
Let me “stretch” this example with a realistic change. I don’t like that you can waste a turn rolling when on net you haven’t done any toggling. (Toggling selects which dice to re-roll, but you can select or de-select a die multiple times before you re-roll.) In terms of state, we’d like to disallow rolling in states Roll1 or Roll2 if there aren’t any dice set to roll.
This code enforces the state transitions but doesn’t have any behavior. Since we want behavior on the actions, we’d add that behavior before calling switchState(). I’d expect that Turn (the context object) would hold or know the data we want to change. I’d also expect to add some extra arguments (e.g., index of which die is toggled).
Your first impulse might be – “We’ve got this beautiful state machine hammer – let’s use it!” Unfortunately, toggling is complicated: there are 2^5 (32) combinations of five dice selected or not. You’d have to expand the events too (to know which die you’re toggling). And I’m pretty sure you’d need a state for each combination. (Consider – you might toggle die 1, toggle die 2, change your mind and toggle die 1 again, then toggle die 2 again, ending up with nothing selected.)
It is easier to enforce this outside the state machine: expand the event with the index, but apply the rules in code. In this case, Roll1 and Roll2 will apply the toggle (dice.toggle(i)) on toggle(), but then only allow the transition on roll() if dice.anyToggled() is true.
Optimization: If states don’t have data of their own, you can use a Flyweight so you create only a single instance of each state.
Critique: This pattern does some things nicely: from the outside perspective, it makes the events central, and hides the state changes. The conditionals you might need in states are dealt with by the interplay between classes. When you want to add behaviors from outside the state machine, it’s pretty clear where they go.
It’s not a perfect solution though: you have a lot of dependency between the context and state classes. If there’s duplication between states, it’s not particularly easy to see or take advantage of. You potentially have a lot of classes since you need one per state.
Conclusion: Interpreter vs Direct Code
I’ve sketched out 7 approaches (in both part 1 and part 2 of this series). A good rule of thumb is that “if there are seven ways to do something, there are probably a lot more.” For any of these approaches, you’ll still have a number of decisions to make.
The big decision is whether to use an interpreted or direct code approach. Interpreters are more flexible but they tend not to give you much insight into “how” the state machine works. Direct code may or may not give you insight. But it’s often easier to begin there, before you even conceptualize what you’re doing as a state machine.
References
“Lex – A Lexical Analyzer Generator,” by M.E. Lesk and E. Schmidt. 1975. UNIX TIME-SHARING SYSTEM:UNIX PROGRAMMER’S MANUAL, Seventh Edition, Volume 2B. Retrieved 2020-10-25.
“Refactoring Challenge: The Amazing Maze,” by Bill Wake.
“Very Fast LR Parsing,” by Thomas Pennello. SIGPLAN ’86: Proceedings of the 1986 SIGPLAN symposium on Compiler construction, July 1986, pages 145–151. DOI: https://doi.org/10.1145/12276.13326