I recall a game design challenge where your only input is a pushbutton. What if your only input is a single textfield? Let’s look at what search engines have done under this limitation. That can give us ideas for intensifying our own stories.
I talk about “intensifying” stories, in contrast to “splitting” stories. (See References.) I want to first focus on the essence of a capability, then devise improvements and extensions of it.
Search engines basically work like this (ignoring ads, monitoring, and lots of other stuff): a web crawler finds pages, and they’re indexed and put into some data structure. Later, a searcher makes a query, and a search system consults the data structure and produces a list of links (and other material) that “match” the query.
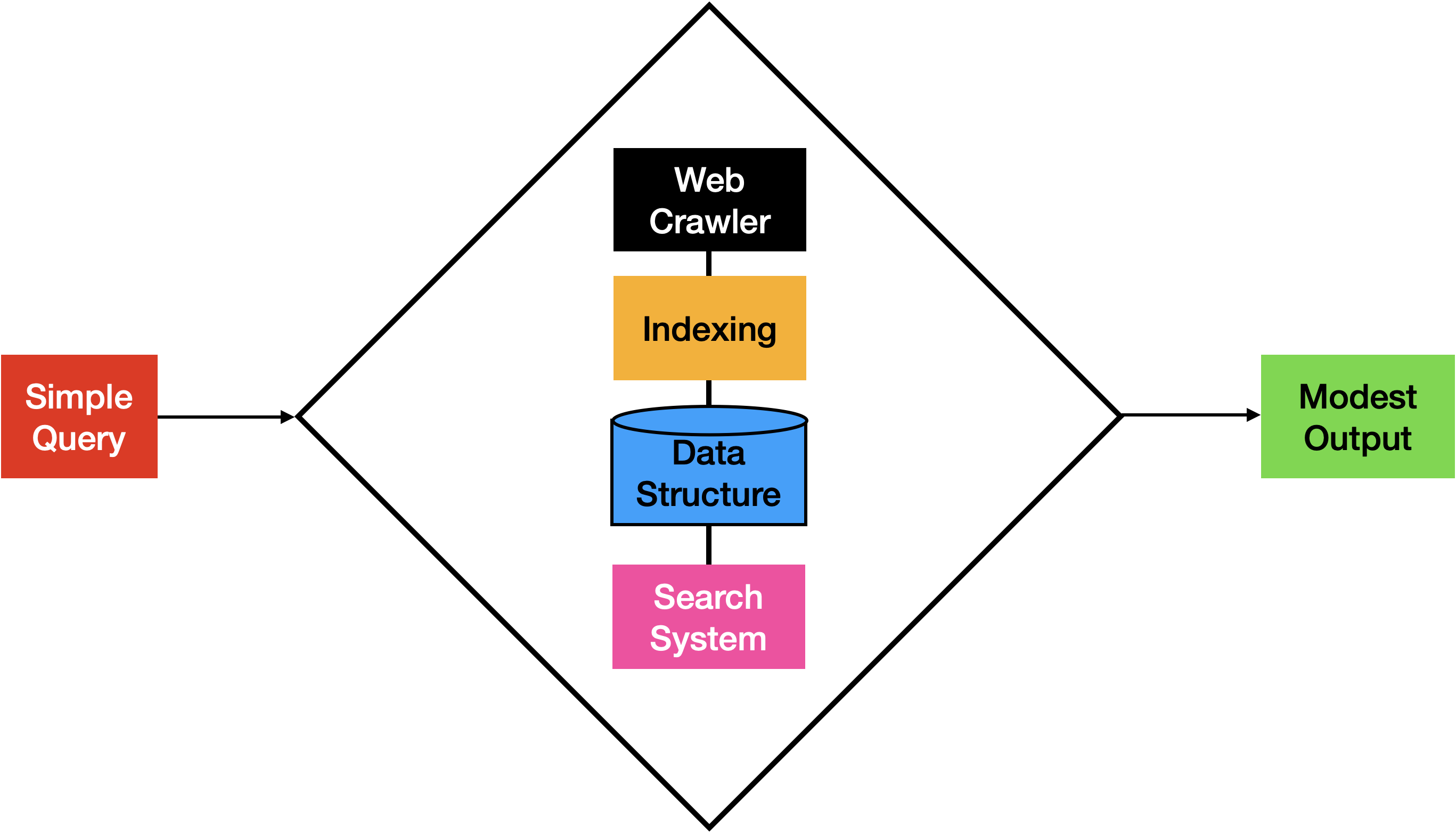
Some applications are “diamond-shaped” like the search engine: not much input, but there’s a whole lot of behind-the-scenes work to generate a modest bit of output. For example, a recommendation engine might take a book title, and use historical data and sophisticated algorithms to generate just the one suggestion that brings in another sale.
Basic Input
A string can have many interpretations. An early release can start with simple ones, then get more sophisticated.
Simple Keywords: Treat the input as a list of words to search for.
Search Operators: Impose a bit of syntax, such as “literal expressions in quotes”, +required words, -rejected words, site:url, boolean operations, and so on.
More Sophisticated Parsers: When certain patterns appear, treat them specially. For example, a numeric formula might trigger a calculator to run.
Pattern Detection: By looking at history, you may see that certain patterns appear such as “weather in ____” or “pizza delivery near me”, and you can interpret those specially.
Intensifying Input
You can use information about previous queries and previous results to fill in suggestions as the user types.
Spelling Correction: Detect and optionally correct a misspelled word.
Word Completion: As the query is being typed, see if a word is a prefix of another word or phrase, and pre-fill it in a way the searcher can either accept it or keep typing what they intended.
Suggestions: You can use previous searches and their frequency to suggest phrases or websites corresponding to what’s been typed so far.
History: You could suggest a query the searcher has used before when they type a prefix of it.
Metadata: You could add information about the query being typed or its hypothetical results, e.g., “searched 4.2M times”, “357K results”, or “preferred 87% of the time”. (I’m not aware of search engines doing this yet.)
Intensifying Analysis
The hidden parts affect the quality of results. In search systems, this includes crawling, data structures, query matching, and more. Your system will probably have completely different subsystems, but there is often scope for more sophisticated results when you take history or other information into account.
These are changes Google has made over time. (See References.)
- The PageRank algorithm used citation data as well as keyword matching to generate better results. (Quality of results.)
- Changes in the crawler to get information on new pages more quickly. (Quality of data.)
- Their analysis has changed over time to try to eliminate “farms”, scraped pages, link-buying, and other low-quality results. (Quality of results.)
- They’ve changed the weight they give various attributes of pages: valuing https over http (security), value mobile-friendly sites (taste shift), penalizing slow sites (performance).
- Google has applied machine learning to queries and results, to take advantage of their huge data sets to build better answers. (Quality of results.)
What I find interesting is that they’re clearly not restricting themselves to an algorithmic view of what a good search result is. What I mean is, they do use particular algorithms and presumably make sure the output is what they expect for some technique, but they take a deeper view of results: results are good if people click them and come back for more. (Or perhaps it’s “good if people click the ads”; I don’t know their metrics.)
Output Sections
There is also cleverness in what’s in the output.
List of Results: The simplest output for a search engine is the list of matching results.
Metadata: You may return metadata about the search or result, e.g. “About 1.2 million results (0.8 seconds)”.
Highlights: Many search systems highlight search terms in the results.
Summaries: Some search systems show excerpts or summaries of the matching documents.
Site Organization: Google often shows the high-level pages of a site, in addition to the particular results.
Direct Answer: Google in particular may extract an answer from pages, to eliminate the need for you to click to get to the results. (This also keeps you on Google’s site longer, which is an advantage for them.)
Ads, etc.: Many search systems provide ads as part of the results, labeled as such or not.
Further Suggestions: The system can suggest alternate or related search terms, so you can easily trigger a new search knowing that the system has something matching.
Conclusion
For diamond-shaped systems, the input and output are fairly limited, but there is a lot of behind-the-scenes work. You can intensify each area: input, processing, and output, frequently by using historical data to make suggestions or tune results.
References
“History of Google Algorithm Updates“. Retrieved 2021-11-28.
“Intensifying Stories: Running with the Winners“, by Bill Wake. Retrieved 2021-11-28.
“The History of Search Engines”. Retrieved 2021-11-28.