How should we handle error conditions? We’ll look at the try-catch exception mechanism that’s similar across many languages, and a few patterns and pitfalls for working with it.
Old-School
One way of handling errors is for a method to have an error code in the return value. For example, in many Unix calls, negative numbers indicate an error.
Experience with this approach reveals a couple common patterns:
- People just ignored errors and hoped they wouldn’t happen. If you ever wrote printf(“hello world”), and not `result = printf(“hello world”); if result < 0 …”, then you’re in that club with me and many others.
- Code that checked all the errors ended up in the “arrow of doom” shape, making it hard to understand what the code was really doing.
if (fd = open(“some.txt”)) >= 0) {
if (result = isEof(fd)) > 0 {
if (result = read(fd)) > 0 {
:
}
}
}
People recognized these and other problems, and experimented with several alternatives. (See Goodenough in the References.)
Goals of a Solution
In designing a new mechanism, we have several goals:
- Important error conditions can’t be ignored
- The code is readable, preferably “straight-line code”
- The mechanism addresses both local and non-local issues
- There’s a way to do cleanup while the error is handled
A Solution – Exceptions and try-catch
One approach that emerged is similar across languages, including C++, C#, Java, Kotlin, Swift, and others: the try-catch construct. (See Java’s specification in the References.) It’s not the only possible solution, and this solution has its critics, but we’ll focus on exceptions and how they’re handled.
An exception is an object that holds information about a problem that occurred, typically a message, plus possibly another exception, a stacktrace, and other information. For example, there are exceptions for dividing by zero, attempting to open a non-existent file, and trying to dereference a null pointer. There’s also a throw statement that lets code fire its own exceptions.
When the error is triggered, an exception is thrown. The exception is delivered to the code that triggered it. If that code does nothing, the current call is exited, and the code that called it gets a chance, etc. If no code handles it, the exception reaches the method in the runtime system that called the topmost method. This has a default error handler that crashes the program.
Any method can have try-catch code to handle the exception:
try {
// some code that might throw an exception
} catch (SomeException e1) {
// code to deal with this exception
} catch (AnotherException e2) {
// code to deal with another exception
} finally {
// code to be run once the exception handling is done
}
The Context
Code that receives an exception typically has methods calling it, possibly recursively:
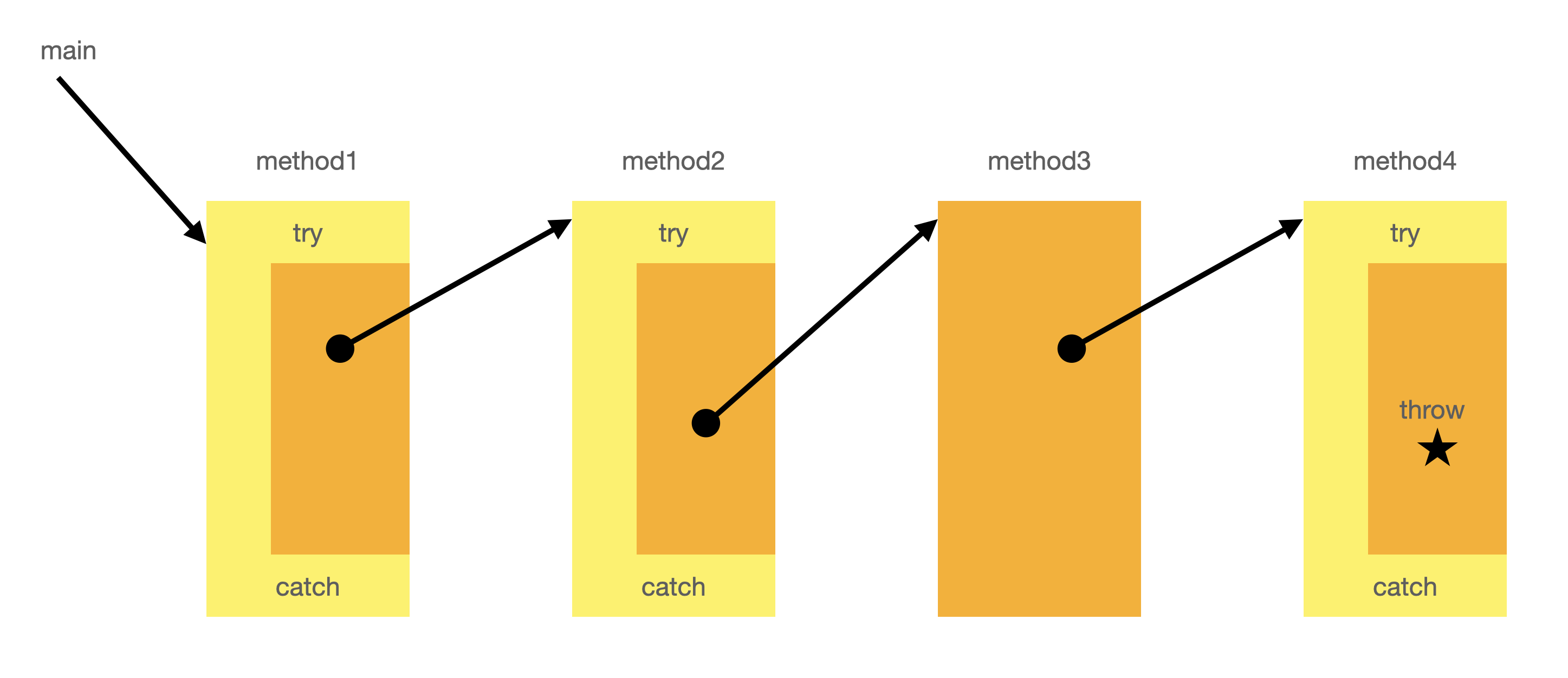
Each call site may have its own resources it needs to free, and its own way of handling an exception thrown by its callees.
Semantics of try-catch
To execute a try-catch statement, start by running the “try” code.
- If there’s no exception, execute the
finallycode and continue from the end of thetry-catch. - If there is an exception, run through the handlers in order, to find one that matches the type of the exception. Note that exceptions are in a class hierarchy, so a
catchof an ancestor exception type will catch any of its descendants. - For the first matching handler that is found, execute its code, and then the
finallystatement. - If no matching handler is found, run the
finallycode, and exit thetry-catchwith the exception. Then any containingtry-catchclauses get their shot, but if none of them handle it, exit the method, and give the calling method its chance (and so on).
The handling code may trigger or throw its own exceptions too. They’re passed to any containing try-catch or escape the method.
Handling Exceptions
When confronted with an exception, what will you do? You have several choices:
- “Swallow” (ignore) the exception, via an empty catch clause.
- Run arbitrary code such as logging, saving information, etc.
- Re-throw the exception to calling methods.
- Wrap the exception in a new exception, and throw that to calling methods.
For the finally clause, you can put any code you want, but it’s mostly there to let you free any resources that you may have acquired along the way.
Two things you might want to do, but aren’t supported by this construct:
- Resume – Handle the exception by fixing up the state, going back to the code where the exception was thrown, and continuing from there. The try-catch construct doesn’t support this (though there are languages that have constructs that do.)
- Retry – You might want to give the try block a chance to try again, either because you’ve done something that might help, or to deal with things like a server that is temporarily down. There is no direct support, but you can create your own facility by putting the whole try-catch in a loop, perhaps with a maximum count and a delay.
Transactional Code
Databases have the idea of a transaction, an operation that either succeeds or fails but never halfway. The classic example is a money transfer: it either removes money from one account and puts it in the other, or it fails without affecting either account.
It’s not exactly the same, but we have similar concerns with exceptions. We need to take care to keep data in a consistent state, and release resources as needed.
Gather and Go
Consider code like this:
read some information (may fail) modify a structure (may fail) read more (may fail) modify more (may fail) read (fail?) modify (fail?) etc.
After the first “modify”, the structure is in a partially modified state until the very end. To be safe, if any exception is thrown, we need to unwind all the partial changes. This can be tricky, and may require that we keep extra information. It may even be impossible – suppose the “modify” were “print to a page”.
To make this code more easily reversible, I use a pattern I call “Gather and Go”: partition the statements so that the “reads” all happen first, accumulating enough information to make the whole change. Then do all the modifications.
Since reads are usually harmless, we thus avoid making any modifications until we know that all reads succeeded.
There are challenges with this pattern:
- It doesn’t always apply – you may have a situation where what is read depends on how the structure is modified.
- It’s not a mechanical refactoring – it requires creativity to change things safely. (It’s typically not a refactoring at all – we’re changing the behavior to act more robustly when things go wrong!)
- If there are multiple modification steps that can fail, this pattern doesn’t help with that.
To make modifications more transaction-like, you may be able to design your structures to take a unit of work (see “Database transaction” and “Unit of Work” in References): a specification of what would be multiple steps, but designed to jointly succeed or fail.
Architectural Concerns
Architectural concerns are the decisions that are hard to change once you’ve lived with them for a while. Exceptions have this flavor. If you don’t use a good and consistent approach, you’ll find yourself with lots of inferior, hard-to-change code.
Some considerations:
- Which exceptions will you catch? (e.g., checked or unchecked if your language has that notion).
- What are your application’s exceptions? Are they in a useful hierarchy that lets you distinguish them as needed? Do they contain the extra information you need for debugging or analysis?
- Will you log? If so, when? As the exception is caught, at every level, or only in its highest handler, elsewhere, or not at all? (I tend to log near the top level, providing that the information in the exception’s call stack can tell me where the problem was and has enough information. Different teams make other decisions.)
- How will you test exceptions? Are there cases you don’t need to check? (Be careful with this – many applications have failures in their exception handling code.)
- How will you avoid code smells in your exceptions? Automatic analysis, code reviews, pairing and/or mobbing, some other way?
You may need to evolve these decisions. However, they’re not easy to change once you have many exceptions in place.
Conclusion
We’ve looked at the basics of exceptions, and the “Gather and Go” pattern that simplifies transaction-style code. Exceptions are typically hard to change, so it’s worth building a consensus on how they’ll be used.
References
“Database transaction”, Wikipedia. Retrieved 2021-12-22.
“Exception Handling: Issues and a Proposed Notation”, by John B. Goodenough. Communications of the ACM, December 1975, pp. 683-696.
“Chapter 11. Exceptions”, in The Java® Language Specification, Java SE 17 Edition, by James Gosling et al. 2021.
“Unit of Work”, in Patterns of Enterprise Application Architecture, by Martin Fowler et al. 2003.