Screen-Based Tests: Two Extremes
Screen-based tests focus on what’s visible rather than internal representations. We’ll consider two extremes for testing screen-based output: fully manual and fully automated. Then we’ll look at moves that can help you evolve from one to the other.
Guru Checks Output

A human tester runs the application manually, and verifies that everything works and looks as expected.
Benefits:
- It’s very cheap to get started. (You don’t have to figure out automation.)
- Humans can notice wrong or suspicious things that would be difficult to automate.
- It can be closer to real use than automated tests. (For example, the speed of use.)
Limitations:
- It takes a lot of time to run tests manually (especially if you’re doing incremental development).
- Humans get bored and don’t pay attention.
- Humans can’t remember exactly how it looked last time or how it’s supposed to look.
- Humans can’t observe very quick or very slow events.
[The name “Guru Checks Output” appears to be from John Farrell, used in the C2 wiki.]
Fully Automated Display-Based Test
A test harness runs the application according to a script, which gives input at appropriate times and captures output. There is a programmatic oracle that decides whether the output is correct, either based on analytic rules, or by comparison to a known-good previous output.
Benefits:
- The system can run the tests relatively quickly (compared to a human doing the work).
- The system can be very consistent in applying oracle rules to decide if the program works acceptably.
- The tests can be run repeatedly. This is particularly valuable in an iterative process, where we want to run the tests hundreds or thousands of times.
Limitations:
- Automating a test is expensive, potentially costing several times as much as running the test manually (e.g., Marick).
- Automated tests tend to be brittle: user interface changes are common, and they require changing tests (sometimes a lot of tests) to reflect them.
- Creating oracles can be very difficult when you’re working from a pixel-level view of the screen; “simple” things like checking for matching text can be AI projects. [Obligatory xkcd reference.]
- The computer has a rigid view of what’s interesting and what’s acceptable. For example, a human might be very aware of flicker during drawing, where the computer may not be sensitive to it.
Note: Some of these limitations are especially problematic with pixel-level output. That gives screen-based tests a bad reputation in many contexts. In the next article, we’ll look at similar patterns, applied at a different level of output.
From Here to There: The Input
The path from manual to automated has many alternatives. We’ll consider three aspects:
- The input: What information and actions flow into the application?
- The capture: How is information captured from the screen?
- The oracle: How do you decide whether the test passed?
Manual Input
The tester runs the application, moves the mouse, clicks, and so on. This is just the input side of a fully manual test.
Captured Input
While the human tester runs the application, the test harness monitors and records their actions. In subsequent runs, the test harness uses the recorded actions as the source.
Some systems do this at the pixel/coordinate level: “The mouse moved to (200, 300) and clicked.” Other systems keep track of the widgets: “The user clicked on the FirstName field.” The latter approach is more robust to UI changes. For example, if the field stays on the same page but moves, a pixel-oriented capture might break, where the widget-oriented one would not.
Programmatic Input
Create test scripts that specify what to do programmatically. Some frameworks encourage low-level scripts (focused on widgets); other systems let you specify at a higher level (which makes test more clear, and is more robust in the face of change). For example:
Navigate to User Profile
Change nickname to Bill
Confirm it
This is at a higher level than the corresponding movements and clicks on the widgets.
The Capture
No Capture
In the purely manual case, the output is ephemeral. The tester sees the output, but it’s not captured anywhere.
Video
You could capture the entire output of a session as a video. I’ve seen this done to capture an exploratory testing session, or for usability testing, but haven’t seen any test frameworks that attempt it.
Snapshot
Rather than taking pictures continuously, take a periodic snapshot of the screen.
Have the human or system execute the test, and periodically take screenshots while the app is running. You can have an explicit “snapshot” action, or you can do it by timer (“every 1 second”), but it is most commonly driven by events. For example, the iOS GUI test driver takes snapshots when the event loop goes idle, indicating that the output is stable.
Taking snapshots lets you speed up or slow down events during playback.
The Oracle
Human Oracle, Real-Time
The easiest oracle is the human tester, interacting with the system, watching the screen, and deciding whether things are working.
Human Oracle, After the Run
Once we are driving the app with either recorded interactions or a script, and are capturing the screen as snapshots, we can get the human out of the real-time loop.
Rather than analyze the system during the run, have the human review the snapshots, with no need to type or navigate. This is usually much quicker than live tests.
Gold Master
With screen shots, it’s hard to specify the expected output in advance.
Instead, we run the system once, capturing its output as the gold master. (It’s prudent to have a human review this output.)
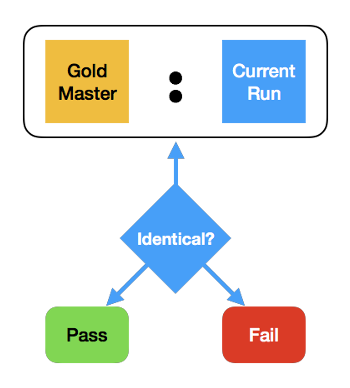
On subsequent runs, we capture the output again, and compare it to the gold master. If it matches, the test passes; otherwise it fails.
On the plus side, this allows for an automated oracle. But it has a limitation: any change in the output makes some (or all) gold masters be obsolete.
We have to be diligent: if we get in the habit of approving any changed output, without reviewing it carefully, we may approve failing tests. This makes our “testing” useless.
Gold Master with Fuzzy Compare
One twist on the gold master is worth mentioning: on some systems, there can be slight differences in output because of video drivers, operating system differences, etc.
To accommodate these differences, we can loosen our comparison to be not as picky about exactly matching.
Bonus Trick: Sequential Comparison

This technique can be helpful either for the human oracle reviewing snapshots, or when reviewing a failure detected by an automated oracle:
Rather than comparing the master and the current side by side, show them sequentially, alternating between the views. Differences between them will show up as motion or flicker. The human eye is good at detecting this.
Conclusion
We looked at two extremes: Guru Checks Output (i.e., a human tester does the work) and a Fully Automated Display-Based Test (record-playback automated test with a gold master). We also looked at intermediate steps, that can take us from one to the other.
Screen-based tests are relatively easy to set up, but they do have limitations. Going from the internal representation to a display loses information. It’s easy to spot differences, but hard to know why they happened. In the next article, we’ll look at more robust tests that make use of the internal structure.
Other Articles in This Series
- “Models: Testing Graphics, Part 1“
- “Displays: Testing Graphics, Part 2“
- “Internal Objects: Testing Graphics, Part 4“